Over the years doing various Skype for Business deployments, or just doing some vanilla web server work, I’ve needed a reverse proxy that was simple and easy to deploy. There are quite a few out there such as HAProxy (my preference), NGINX, and then some commercial products like KEMP. However, the deployments I was doing didn’t really need the investment of a major appliance, and some of the users I was working with preferred to steer clear of Linux/Unix systems, so a great choice for this is IIS Application Request Routing. This is a simple reverse proxy that, after a few tweaks, can do the job well with minimal effort.
However, I wanted to get a little more complicated with the reverse proxy and it’s URL rewrite rules, so I decided dig in and figure out the URL rewrite logic a little better, which is the focus of this post. This is going to be GUI focused, but there are certainly better ways to do this via XML, but this was the easier approach that I took at the time.
(If you’re looking on how to set up IIS ARR, check this blog out, read the documentation from Microsoft on IIS ARR, or google it.)
Simple goals here:
- Create two rules to reverse proxy the “cookies” and “cupcakes” traffic to the web server, both for HTTP and HTTPS
- Create a catch-all rule to send everything else to giantmidgets.org
Setting Up HTTP Reverse Proxy Rule/Back-References Demonstrated
After setting up the server farms that the URL rewrite will direct traffic to, go to the root of the server and open up ‘URL Rewrite’, then I clicked ‘Add Rule(s)…’
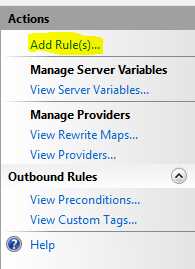
I went ahead and selected ‘Inbound Blank Rule’. I want to keep this simple.
I named it something useful (I’m creating a rule for HTTP and HTTPS separately). Then I put in the pattern I needed:
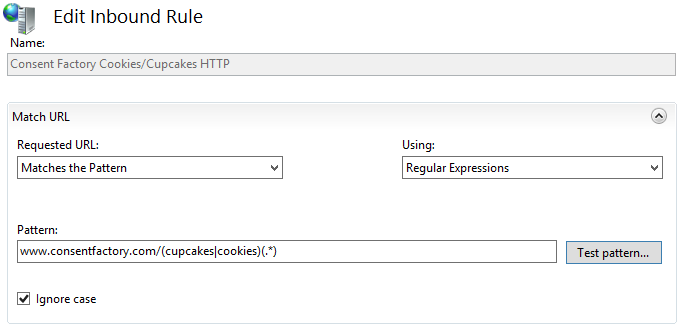
This is a regex that looks for anything with “www.consentfactory.com/”, and for the URL path to either have “cupcakes” or “cookies”, then whatever string is available after that.
Next, I set up my conditions:
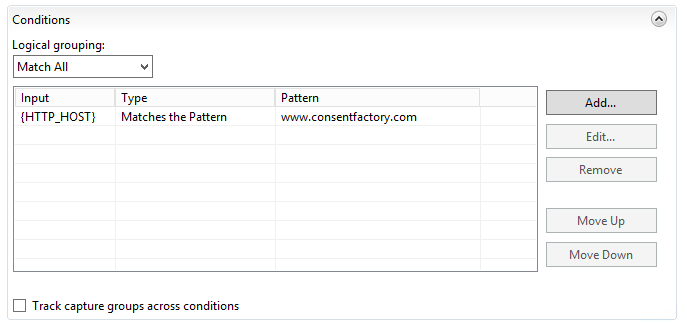
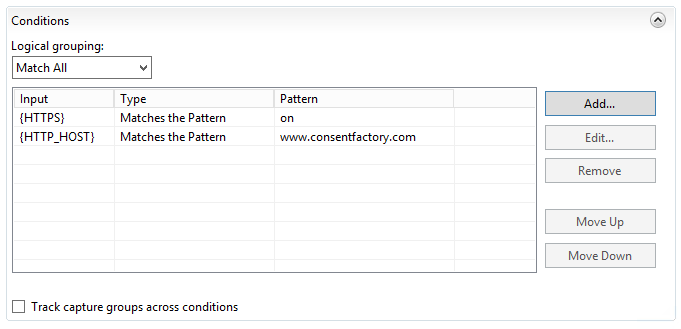
The condition basically requires the FQDN to be present. Next comes the routing rule:
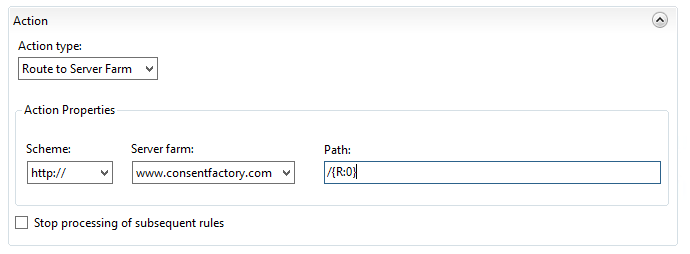
Here I’m stating that the action type is to route to the server farm (basically the ARR component of this), then to send it as HTTP with the path taken from after the FQDN of the request. However, note the “Path” field; it says “/{R:0}”, but what the heck does that value come from? To see that value, click on ‘Test Pattern’ up at the top of the rule under ‘Match URL’:
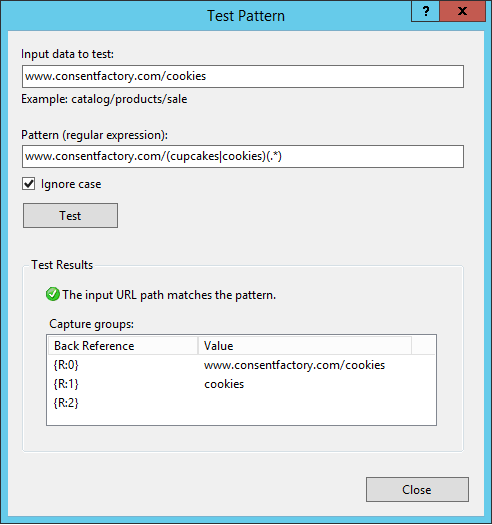
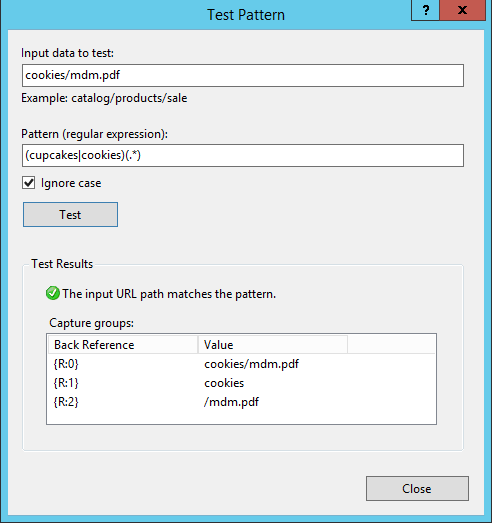
Input the URL that you’re trying to reverse proxy in the ‘Input data to test’ field, then click ‘Test’. This is actually how you can see those ‘{R:X}’ values will be derived. These are called ‘back references‘, and the format ‘{R:X}’ refers to matching rules from the ‘Match URL’ section. {R:0} will always contain the entire string being sent, which is why my routing action for routing to the web server is incorrect because if I were to leave it like that, anything after the FQDN would be sent, which currently would add “/www.consentfactory.com/cookies” to “www.consentfactory.com”, looking like “www.consentfactory.com/www.consentfactory.com/cookies”.
There are two ways to fix this.
One approach would be to just correct the routing action to use {R:1} and {R:2}, like this:
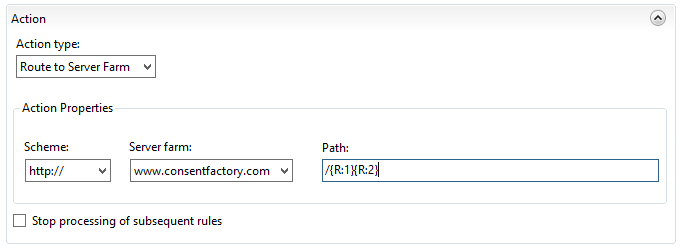
However, my preferred approach is to keep the regex more simple, which allows us to use the original routing action of {R:0}, so I configure my regex URL matching to look like this:
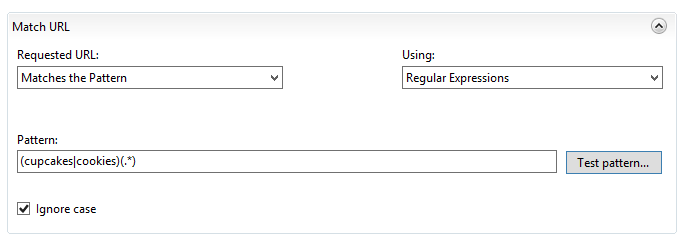
Which tests out our back-reference values to look like this, thereby allowing the {R:0} rule:
Now that’s done, the HTTP rule is set up. The only thing left is to set up the HTTPS rule, and a catch all for anything that isn’t in a subdirectory.
HTTPS Reverse Proxy
The HTTPS rule is the same as the HTTP rule, except we adjust the condition to look for HTTPS being used like this:
The routing rule will be configured like this:
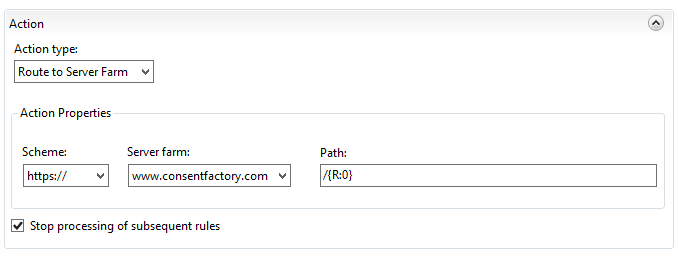
Catch-All Redirect Rule
Finally, I’m creating a rule to just catch anything that isn’t a specific subdirectory of consentfactory.com. The rule will be the same as the HTTP rule, but the routing action will actually be a redirect somewhere else, like this:
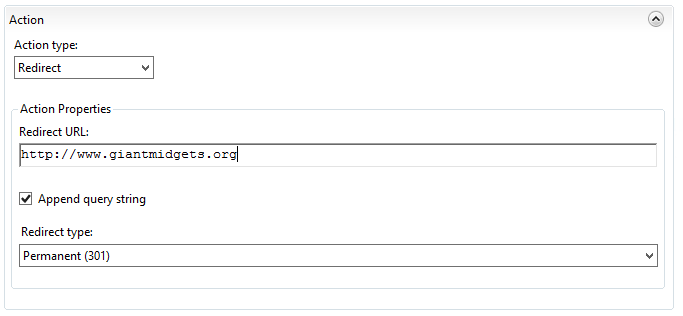
Hopefully this helps explain that process a bit. It helps me to see examples, so maybe this will help others.
(Edit (20171023): my HTTPS routing rule image was incorrect. It didn’t use “https://” for the ‘Scheme’, which is what we want it to route to.