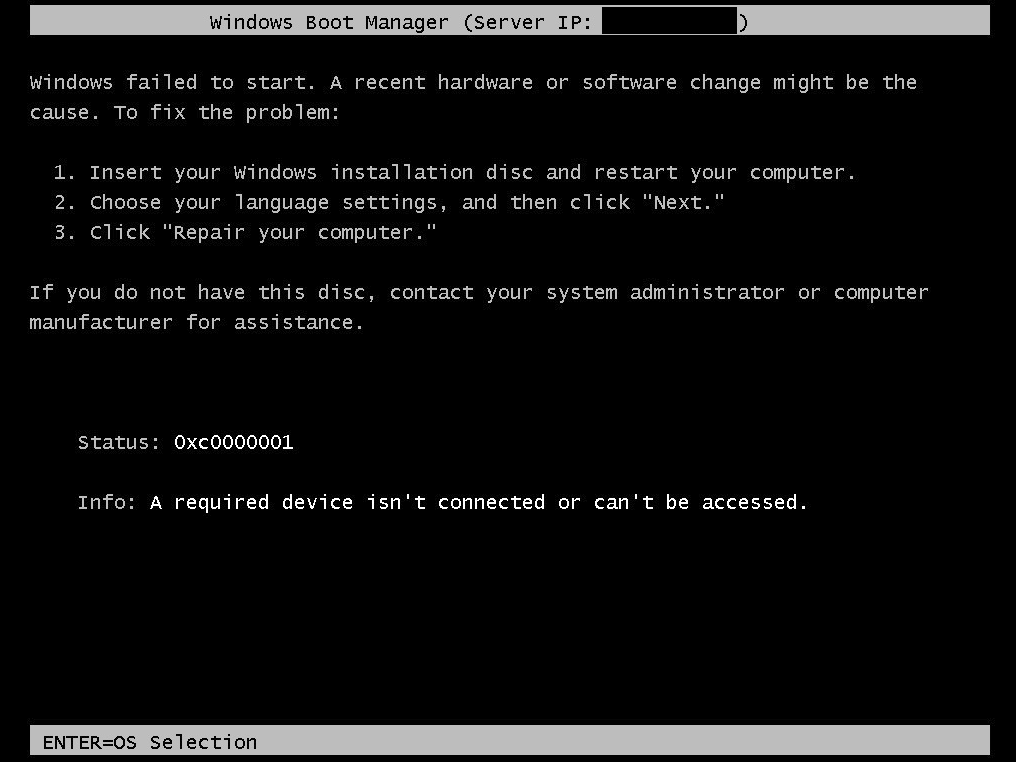
When you’re imaging/PXE-booting in SCCM, I think the “0xC0000001” error is one of the strangest errors to troubleshoot, because the source of the error is related to some problem/conflict between TFTP and the network adapter of the machine you’re imaging — but then sometimes it has to do with the network adapter of your distribution point.
I have encountered multiple solutions to this problem, and here are some of them from other blogs:
Windows Updates breaking PXE. Per a colleague, KB4489881 is known to cause problems, but I have heard reports that even the fix to KB4489881, KB4503276, is causing problems.
Solution: Uninstall the updates.
There are others.
However for me, I had the following scenario, and my solution turned out to be quite simple.
Context:
Trying to image Pentium-based, 4 GB HP ProBook x360 11 G1 EE laptops
From a VMWare DP, the machines receive the boot image just fine.
From a Hyper-V DP, ‘0xC0000001’ error occurs on these laptops.
For the sake of curiosity, I did the three items above (change reg key, changed network adapter properties, and even reinstalled WDS). None of these worked.
I reverted all those settings and put the DP back in a ‘vanilla’ state
I found this behavior to be really odd. Why would it download the boot image on one just fine, but not on the other? Perhaps the boot image needs network adapter?
Well, it turns out the solution for this model laptop was to add the network adapter driver* to the boot image. We generally don’t add network drivers to boot images unless necessary, which in this case it turned out it was.
And that was that. If you don’t know how to add drivers to the boot image, I’m not going to reinvent the wheel, but I will direct you to this website that has a decent how-to.
Happy SCCM-ing!
(Edit 20180710 – clarified the use of a driver)
(Edit 20190702 – Added Windows Updates as a potential cause).
One PITA problem to deal in SCCM with when deploying large application installs like AutoDesk Inventor or Adobe Creative Cloud is the sheer size of the install, which can be 10-20 GBs in size. Well after a fellow Twitterer asked about zipping packages and so forth for deploying large packages and applications in SCCM, I responded with something I do at my organization, and thought I’d share the info. This probably isn’t really anything new, but it’s what I’ve done to solve the problem.
I couldn’t think of an image for this post, so you get Gizmo.
Deploying large packages over the network can take awhile; one solution to this is to compress the contents into a package/application, deploy the compressed contents with the 7-zip executable (and dll), then use the 7-zip .exe to uncompress the contents on the remote device. After the install is complete, just remove the uncompressed contents, and Bob’s your uncle.
This requires the 7z.exe and 7z.dll files, and of course the compressed package in whatever format you want (I prefer .7z).
Below is a batch file I use to perform this task, and I’m using AutoDesk Inventor 2017 as an example. I also have a Github page that has the complete install and uninstall for AutoDesk Inventor.
(Note: For some reason I wrote this up in December 2017 and never published it. Maybe I forgot to add some links, but I put the work in and it seems to still be relevant. As noted in the bottom, this should have been resolved in 1802.)
Last week I had some SCCM woes with the peer cache feature, the gist of which is that application install steps during OSD would effectively stall out. Why? That was the great mystery that had me sweating overcaffinated bullets as people out in the field are notifying me and my boss that they can’t image, and of course at a time when certain important devices need to be imaged.
“Why in the world is this not working?” I asked myself. I can only presume it was the result of me enabling the feature across our organization, but there’s more to the story than that.
I know what you’re saying: “Did you freaking test it before deploying it?
Of course I did. I had spent the last few months testing BranchCache and Peer Cache in a lab setup and then in a local site. They both were working well, and I had no indications that either was causing a problem. In fact, I was able to measure noticeable improvements in application and software update delivery as a result of enabling the changes! However, I never had an issue with OSD in my lab or at the site I tested, and so I had no idea to expect it.
What I encountered in CAS.log during OSD was this on all the affected machines:
And quite a bit more than that, but this is what peer caching is supposed to do. It effectively creates a bunch of mini-DPs across your boundary group, but there’s one problem that I didn’t take into consideration, and it’s why my environment that I tested in didn’t have this problem but the problem appeared in production: we have a TON, and I mean a TON, of laptops, and those laptops are mostly in carts powered off or (hopefully) sleeping. So peer caching may not work for us.
But then why didn’t the distribution point take over? Why didn’t the client download from it? No idea, but I needed to move on, fast.
After seeing those logs (note the name of the URL has “BranchCache” in it, but it’s actually peer cache, but I didn’t know this at the time) and knowing the change I made recently, I figured I’ll just reverse the changes and it’ll be all good, right?
We got this. We’ll just reverse the changes.
Wrong.
Well then what the hell is going on?
Feeling even more under the gun now that I’m completely baffled with what’s happening, I engage with Microsoft Premier support because I feel that I could keep plugging away and googling the problem to death, or I could cut to the chase and get Microsoft involved.
Microsoft gets in touch with me, and after going over all the information I sent them and looking over the logs I was noticing, the tech fairly quickly identifies the issue as being a problem with the current build of peer cache (as of 2018.11.01-ish). Apparently even though peer cache is disabled in client policy, the changes don’t actually work and the database in SCCM still contains all the super peer entries. The fix that resolved it was to delete the super peers out of the DB with these SQL query/commands:
delete from SuperPeers
delete from SuperPeerContentMap
Bam! The problem was solved. Mostly. Kind of. The tech thought OSD was working, so it must be fixed.
The problem though is that the database keeps getting full of super peer information, so it needs to be routinely cleared out, and the super per clients need to update their super peer state. So after following these twoblogs, and then getting annoyed with cleaning the DB manually and updating the collection, I put together this crude script as a scheduled task to take care of it.
(Edit 20180525): To run this script, you’ll need a few prereqs:
PowerShell 5.1. This was tested running on that version. You can find your version by typing $PSVersionTable in a PowerShell terminal. This may work on earlier versions, but I never tested this on earlier versions.
SCCM Admin console installed on the machine you’ll run this from.
You need the SQLServer module installed. Assuming you’re on PowerShell 5.1, you can get it by just running ‘Install-Module SQLServer’, then import it in with ‘Import-SQLServer’.
Finally, you’ll need to adjust the script for your own local information (site code, servers, etc.)
(Edit2 20180529): After reading this over again, it might be helpful if I explain what my script does, at least a high-level. The comments in the code explains what it does at a line-by-line level. What the script below does:
Imports modules needed (SCCM and SQL)
Reads superPeers.txt and performs a SQL query to get current Super Peers, then concatenates both ingests
Creates a SCCM collection based on the resourceIDs that we just ingested
Invokes a client update notification telling the Super Peers to update their client policies
Keeps a list of all resourceIDs used for this process
Deletes the Super Peers and Super Peers mappings from the database
The basic idea is to get these various devices out there to update themselves and to clear them out of the database, otherwise other devices may try to still use them as Super Peer/mini-DP.
Next, what I’ve done is run this script in an elevated prompt, and then let it do it’s thing.
Script:
# Set Date for future use
$date = Get-Date -Format yyyyMMdd.HHmm
# Import ConfigMgr Conosle Module
Import-Module "$($ENV:SMS_ADMIN_UI_PATH)\..\ConfigurationManager.psd1" # Import the ConfigurationManager.psd1 module
# Import SQLServer Module (Forgot this, thank you RiDER)
Import-Module SQLServer
# Starting transcript to keep track of what the heck is going on
Start-Transcript -Path "<path to file>\superPeerCacheCleanup\superPeerLog_($date).txt"
# Setting global 'WhatIf' and 'Verbose' parameters for testing or output
$WhatIfPreference = $false
$VerbosePreference = "Continue"
# Collection name that will contain peers
$collectionName = "Super Peers"
# Getting contents of text file that already contains Super Peers that we've already queried for
$superPeers = Get-Content "<path to file>\superPeerCacheCleanup\superPeers.txt"
# Run SQL query to get the resourceIDs of the Super Peers, and adding a comma to the end of resourceID gathered
$resourceIDS = (Invoke-Sqlcmd -Query "select * from SuperPeers" -ServerInstance "localhost" -Database "<SCCM DB>" | select resourceId -ExpandProperty resourceid) -join ","
# Combine the contents of the Super Peer text file and SQL query into an array
$newResourceIDS = $superPeers + "," + $resourceIDS
# Create the query rule that we'll use to indicate the membership for the SCCM collection
# This query sets the membership based on the resourceIDs that we gathered and concatenated earlier
$collectionQueryRule = "select SMS_R_SYSTEM.ResourceID,SMS_R_SYSTEM.ResourceType,SMS_R_SYSTEM.Name,SMS_R_SYSTEM.SMSUniqueIdentifier,SMS_R_SYSTEM.ResourceDomainORWorkgroup,SMS_R_SYSTEM.Client `
from SMS_R_System where SMS_R_System.ResourceId in (" + $newResourceIDS + ") order by SMS_R_System.Name"
# Set the PSPath Site Code Location. This is needed because running the SQL query changes the path to 'SQLSERVER'
# Probably a better way of doing this, but this works for this purpose
Set-Location "<SITECODE>:"
# Capture the collection query rule into a variable. I couldn't get the pipe to work correctly for removing the rule
# so I'm just capturing it as a variable.
$membershipRule = Get-CMCollectionQueryMembershipRule -CollectionName $collectionName
# Remove the collection query membership rule in order to create and update the collection with a new one
Remove-CMCollectionQueryMembershipRule -CollectionName $collectionName -RuleName $membershipRule.RuleName -Confirm:$false -force
# Updating the colection with the new query membership rule that we create above
Add-CMDeviceCollectionQueryMembershipRule -CollectionName $collectionName -RuleName "Super Peers $($date)" -QueryExpression $collectionQueryRule -Confirm:$false
# Tell SCCM to update the membership of the SCCM collection
Invoke-CMCollectionUpdate -Name $collectionName
# Pausing for a moment to allow SCCM to update the membership of the collection. This is an arbitrary time; could be shorter/longer.
Start-Sleep -Seconds 60
# Creating a backup of the old Super Peer list
Copy-Item "<path to file>\superPeerCacheCleanup\superPeers.txt" "<path to file>\superPeerCacheCleanup\superPeersOld.txt" -Force
# Deleting the super peer list.
Remove-Item "<path to file>\superPeerCacheCleanup\superPeers.txt" -Force
# Creating a new Super Peer list based on combining the old values and new from the SQL query
Add-Content -Value $newResourceIDS -Path "<path to file>\superPeerCacheCleanup\superPeers.txt" -Force
# Sending a client notification in order to tell the new Super Peer clients to run the Super Peer state script
Invoke-CMClientNotification -DeviceCollectionName "Super Peers" -NotificationType RequestMachinePolicyNow
# Deleting the Super Peer values from the SCCM DB
Invoke-Sqlcmd -Query "delete from SuperPeers" -ServerInstance "localhost" -Database "CM_PRI"
Invoke-Sqlcmd -Query "delete from SuperPeerContentMap" -ServerInstance "localhost" -Database "CM_PRI"
# Ending the transcript
Stop-Transcript
Update: As of December 2017, the issue still persisted, which might have been because the clients weren’t getting their client policies updated, so the Microsoft tech had me recreated some of the client policies and deploy them. The issue seems to have been fixed as those dang laptops start getting powered on. The tech also informed me that this behavior is resolved in SCCM 1802.
Also, I suspect that the issue was not only due to laptops becoming superpeers and not being powered on, but also because the boundary groups configured were too broad and spanned too many sites. Not the primary issue, but it definitely contributed to it.
We have continued to use BranchCache and it’s amazing how well BranchCache is working in our organization, even with a ton laptops in carts (45-53% of content source comes from BranchCache at these sites).
A few weeks ago I had the pleasure of attending Microsoft Ignite 2017 in Orlando, Florida, one of the best and well-organized conferences I have ever attended. There were a ton of sessions to attend for people of all backgrounds in IT, so I couldn’t hit them all (thankfully they’re posting the sessions on YouTube).
It’s a juggling act at events like this to strike the balance between personal interest and getting information/training to add value to the organization that sends you, so I focused on Windows 10 Deployment, Azure IaaS, and whatever Powershell nuggets I could find. All three topics are too much for one post alone, so I wanted to dump some thoughts on one that stuck out the most: Windows 10 Deployment.
Creeping from the Old to the New: Windows 10 Deployment
Device deployment in the Microsoft world has been dominated by what they call “traditional IT”, which we in the SCCM/MDT world would just call imaging. The “traditional” method of deploying devices often involved a lot of preconfiguration before the device actually reached the end-users, often with BIOS updates/configs and the tried and true method of wipe and load.
Of course, at Microsoft Ignite, you’re going to get proselytized about the company’s newest technology, and the direction Microsoft is transitioning to is something they call “modern IT”. It’s best summarized in this slide from Michael Niehaus’session on deploying Windows 10:
In practice, what this actually looks like is a bit of gradient between on-premise and cloud-based services, but the direction Microsoft is taking is to move identity services to Azure Active Directory, device management to InTune, applications are deployed from the Windows Store, and updates are managed via Windows Updates for Business. The entire process initiated on end-devices after a user logs into a device with their email and password with an Internet connection, removing the need for special provisioning. The entire process is summarized into what Microsoft calls “Windows AutoPilot“.
However, what I took from AutoPilot and all the deployment sessions was that while Microsoft would love for organizations to move their deployments online and sign-up for that recurring revenue, they know this is still a little ways off and doesn’t offer the feature parity of AD/SCCM. So instead, they’ve designed InTune and SCCM to really work in what they call “co-existence”, which comes from using the old and new methods together as a form of transition (to varying degrees): InTune-SCCM-AAD, or InTune-SCCM-AD, or (insert combo). The idea here is to not go full cloud, but transition to it to some degree.
One of the deployment MVPs who represented Microsoft explained it to me like this. Microsoft’s story about centralized Windows management has been largely one-sided for over 20 years: SCCM or nothing. There was no middle-ground between nothing and SCCM (although you could cobble-up some combination of AD, MDT, and scripts). InTune, AutoPilot, Windows Store — the combination of it all presents a middle-ground, a sort of gradient to centralized management. If you want a lot of control over your devices, continue using SCCM; if you want something simple, you have InTune now.
I think what Microsoft has done is make an interesting case for “modern” deployment, but until their on-premise AD component is deployed and fully-tested, I just don’t see a compelling case to even try InTune yet. The current deployment process, while not perfect, works pretty well, so this would have to be hardware that is proven to work well. Past experience makes me skeptical that hardware will work as well and consistently as SCCM OSD does (then again, I’m not working with users across the globe, so maybe there’s a better case to be made in that scenario).
Modern Windows 10 Deployment and Education
Bringing this closer to the industry I currently work in, Microsoft’s case for Windows 10 deployment and management for education is strong and better than ever before. Windows AutoPilot is indeed a great way to deploy devices (no matter which way you approach it), Azure AD and Office 365 are stellar products, OneNote is awesome (best education tool I’ve seen), Microsoft Teams looks amazing (especially with its takeover of Skype for Business and integration with Microsoft Classroom), and Microsoft’s licensing is making a big change. The classroom tools are indeed there, and management is as easy as G Suite (IMO).
However, I can’t help but ask: has the ship already sailed for a lot of K-12 organizations? I mean, Microsoft certainly has this great product for K-12, but a lot of organizations have already made massive investments in their device purchases, the technology choices they’re using in the classroom, and the email/cloud platform that they’re running applications with. These organizations already have inertia in the direction of these choices, so does Microsoft have enough to unbalance this forward motion?
I personally don’t think so, at least for the G Suite organizations. These organizations chose G Suite (or Google Apps at the time) largely because they could purchase educational devices for cheap, thereby getting more devices into student’s hands, and Google’s services (which users organically learned to use over the years) was free. Around the same time, Office 365 licensing was confusing, and while there were some free options, the service parity for device management just wasn’t there compared to G Suite.
Fast forward to today, and the case for medium and large education institutions moving to Microsoft 365 is more compelling in the context of data security. The new A3 and A5 pricing structures from Microsoft bring with them EMS, thereby allowing greater data loss protection and services. Meanwhile, Google removes feature parity between it’s Education and Enterprise products, requiring organizations acquire the Enterprise suite at $25/user per month for services such as DLP.
Maybe it’s the Microsoft Ignite kool-aid in my system, but Microsoft has a better case for it’s products than Google with it’s licensing combos, or maybe Microsoft is just better at marketing and promoting it’s platform than Google. In the education world, I hardly ever hear from Google themselves promoting their products, it’s always someone doing something randomly. Microsoft constantly makes contact with my org, but Google — not a peep.