If you’re running a Palo 5200/7000 series firewall, you may have inserted transceiver modules and the only way you really know they’re recognized is if you get them online. While troubleshooting an issue, I found a item from the Palo Alto KB, namely the log file brdagent.log is where you can view the transceiver you inserted; the log itself is for monitoring interfaces and other networking chips being inserted (see book link below).
To view the log, I prefer to use the tail command to view the log, which is a Unix/Linux command to view the last section of the log file, and even to watch the log file as it’s being used.
The command:
tail lines 100 follow yes cp-log brdagent.log <bunch of log files> cp brdagent.log 2019-10-03 17:10:40 2019-10-03 17:10:40.001 -0600 Port 25: Down 40Gb/s-full duplex cp brdagent.log 2019-10-03 17:10:40 2019-10-03 17:10:40.001 -0600 PORT25: board_port_autoneg_enabled -> board_port_autoneg, link: 0, mode: 1 cp brdagent.log 2019-10-03 17:11:40 2019-10-03 17:11:40.644 -0600 Error: gryphon_get_port_info(5200/gryphon_ports.c:1231): Remote fault detected on port 25! cp brdagent.log 2019-10-03 17:13:22 2019-10-03 17:13:22.156 -0600 Port 25: sysd_obj_lookup for <QSFP> failed !!! cp brdagent.log 2019-10-03 17:13:22 2019-10-03 17:13:22.156 -0600 Port 25: Empty QSFP+ detected cp brdagent.log 2019-10-03 17:14:07 2019-10-03 17:14:07.441 -0600 QSFP+ detected on port 25 cp brdagent.log 2019-10-03 17:14:07 vendor 'FINISAR CORP. '; part 'FTL4E1QE1C-A5 '; id 'QSFPP'
The command broken down:
tail – the Unix/Linux command that displays the last section of a file
lines 100– displays the last 100 lines (or less) of the file
follow yes – informs the cli to continue printing any additional input to the file
cp-log– this is a directory for control plane logs, and according to Tom Piens with the Mastering Palo Alto Networks book below, there a few different directories for the management plane, data plane, and other logs. The log directories will vary based on models.
brdagent.log– the log filename.
As you see in the log above, you can see the the QSFP transceiver in the log. Using the tail follow command though, you can watch as transceivers are inserted, like this (I inserted a Cisco twinax as an example):
2021-05-25 13:50:34.663 -0600 Port 19: SFP Plus Empty detected 2021-05-25 13:50:51.756 -0600 Port 19 :: sfp_data.transceiver_codes(str) = 10000 2021-05-25 13:50:51.756 -0600 SFP Plus detected on port 19 vendor 'CISCO-TYCO '; part '2053783-3 '; tc '10000' 2021-05-25 13:50:51.757 -0600 Port 19: SFP Plus Fiber detected 2021-05-25 13:50:51.757 -0600 PORT19: board_port_sfp_nopop_0 -> board_port_startup, link: 0, mode: 2 2021-05-25 13:50:51.761 -0600 PORT19: board_port_startup -> board_port_autoneg, link: 0, mode: 2 2021-05-25 13:50:51.764 -0600 PORT19: board_port_autoneg -> board_port_autoneg_linked, link: 1, mode: 2 2021-05-25 13:50:51.764 -0600 Port 19: Up 10Gb/s-full duplex
Yes, you can other vendor/third-party transceivers in Palo Alto firewalls. Palo Alto publishes the details of the transceivers here. I haven’t ever encountered issues with other vendor transceivers, but that said, getting support if you have an issue and the transceiver is potentially the problem may not result in support from customer support.
While troubleshooting an HSCI port, I found that I could test if the optic was functioning correctly from the HSCI connecting the port to a switch and configuring layer 2 connectivity (ethernet). The transceiver responded, which makes sense because the configuration in HA sets the transport for HSCI as ethernet. Even though Palo says, “[t]he traffic carried on the HSCI ports is raw Layer 1 traffic, which is not routable or switchable. Therefore, you must connect the HSCI ports directly to each other (from the HSCI port on the first firewall to the HSCI port on the second firewall),” I found the HSCI at least responds to ethernet. So perhaps they mention this to indicate you shouldn’t bridge the connection (via layer 2 switch).
If you’re not getting complete session sync between a pair of HA firewalls, and even though your HA is showing as up, you should perhaps check your transceivers, particularly if you’re using non-Palo Alto transceivers.
There was a weird issue when I first joined my current job: I was told was that because of the way Palo Alto GlobalProtect (GP) and Microsoft Skype for Business (SfB) works (or maybe was configured?), I needed to log-in to SfB first, then connect to the GP VPN. The rationale was that SfB wouldn’t connect, or it would take a long time to connect, AND THEN even after a period of time, SfB would start behaving weird and it’s Exchange connectivity would drop, so SfB wouldn’t get voicemails, missed calls, etc. Just all out weirdness going on. It’s 2020, so maybe some of this true to form for the year, but probably not.
Full stop. I’m sure you’re asking yourself right now, “Why not just migrate to Microsoft Teams? Get rid of that whole on-premises stuff.”
Let me answer that in a meme:
Skype for Business is one of the integrative technologies that spans lots of technology stacks that isn’t exactly easy to just jump ship from, and Teams as a VoIP replacement is arguably not there yet.
Also, have you seen the UI comparisons? Going from a sleek floating window for calling, IM, and conferencing with SfB to the giant-lets-pack-lots-of-services-into-one-large-window that is Teams is kind of a hard sell on the user training side of things. Maybe I’m biased. Maybe, but I digress.
The Challenge
Ok, back to the GlobalProtect and Skype for Business issues.
I was admittedly puzzled that the solution — to instruct users to sign-in to SfB before they sign-in to the VPN — was the best solution; it doesn’t seem right from a user experience perspective, and then when you toss-in the sudden weird issues with Exchange connectivity, none of this seemed right, and I doubt that’s the ideal experience. So I brought this up and the team basically said, “we just haven’t had time to troubleshoot it, but if you want to figure it out, go for it.”
You know what that sounds like? An adventure. An itch to itch. Something to solve. A challenge! There could be only one response:
Why Split Tunnel Skype for Business?
Something you might be asking is “Why configure split tunnel in the first place? Isn’t split tunneling a headache to manage?”
Split tunneling can definitely be a PITA, but like a million IT questions out there, the answer ultimately to this is, “it depends.” From my experience, split tunneling becomes difficult when you have a lot of split tunneling to manage, but if you have one or two services, it’s not that bad.
For Skype for Business, it’s one of those technologies that is sensitive to jitter, latency, and packet loss. Why? It’s because it’s voice traffic, and just like voice traffic on the inside of the network, where there’s jitter, latency, and/or packet loss, users on opposite ends of calls/conferences will experience this as delayed audio or parts of the conversation will just break up and it leads to an overall poor experience.
When you configure split tunneling, particularly for technologies like SfB, you avoid the dual encryption scenarios and you allow the technology to use its own optimized methods for connecting voice and application traffic by letting the software connect to services over the internet directly versus through a tunnel.
Baseline
That said, what’s the baseline here? How is GlobalProtect configured with split tunneling and what issues are there?
For GlobalProtect, the split tunnel configuration was configured pretty much like this documentation from Palo Alto (using just the application split tunnel, nothing else). It looked like this:
Here are the issues that were encountered in this setup:
Connectivity issues if connecting SfB after GP VPN is connected
Exchange connectivity in the SfB client drops after a duration of time, even if connection is established before VPN connection
Call transfers working inconsistently
Application sharing working inconsistently
Conference meetings working inconsistently
Issues 3-5 really came later because they were hard to pinpoint due to their inconsistency, but issues 1 and 2 brought some fast wins.
Let’s get to some solutions.
Solutions
Solution for 1 and 2: DNS. It’s always dns.
It’s kind of a joke, but DNS really does cause a lot of problems, and in a split tunnel configuration when you’ve split-tunnel the traffic by application, the application is still going to resolve addresses by the servers you specify in the GlobalProtect configuration. So if you haven’t changed DNS records, the application will split tunnel, but it will still try to connect to internal resources because that’s the records it has.
I don’t have a PCAP screenshot for this, but if you pull up Wireshark and look at the PCAPs for your network interface (non-GP interface), you’ll see attempts to get to SfB internal IP addresses that aren’t (typically) on your network, and thus services fail.
The solution is simple: for your VPN clients, serve the external IP addresses for A records being queried. I solved this by setting up dedicated DNS servers for VPN clients, then just creating the zones and root records for each FQDN. I did this for all the Skype for Business external IPs (edge and reverse proxy) and the external Exchange records.
After doing this, problems 1 and 2 went away because hostnames were being resolved correctly.
Solutions for 3 through 5: Firewall rules and IP Split Tunneling
Problems 3 through 5 were frustrating like no other because I couldn’t really narrow the problems down exactly. Some people had no problems with call transfers, application sharing, or conferencing, but then sometimes they would. So the thing to do is dig into the logs, and when I did I encountered a lot of this:
ms-diagnostics: 23;source="mediationServer.contoso.com";reason="Call failed to establish due to a media connectivity failure when one endpoint is internal and the other is remote"
Or
ms-diagnostics: 24;source="mediationServer.contoso.com";reason="Call failed to establish due to a media connectivity failure when both endpoints are remote"
Or even better:
ms-client-diagnostics: 52049; reason="Leaving app sharing because re-invite failed";UserType="Callee";MediaType="applicationsharing-video"
These all pointed to firewall issues, and even the ICEWARN messages noted something wrong with STUN, TURN, NAT, etc.
So I did some digging and found that firewall rules needed to be in-place to prevent VPN clients and internal SfB servers from communicating with one another. So I added some PAN policies, and things got better, but not perfect. Also, I added the external SfB IP addresses to the split tunnel in Network > GlobalProtect > Gateway > Agent > Client Settings > Client-Config > Split Tunnel > Exclude (which basically just adds static routes in the Windows routing table to send traffic for those IPs out the non-tunneled interface). Still the occasional error creeping up, and I could even witness it, but still can’t quite nail the problem.
Finally, I had a thought: why not get rid of the application process split tunnel? I mean, if I have DNS addreses configured, and IP split tunneling working, why is the application process split tunnel needed? Removed that from the setting and bam — all the problems went away. Like magic.
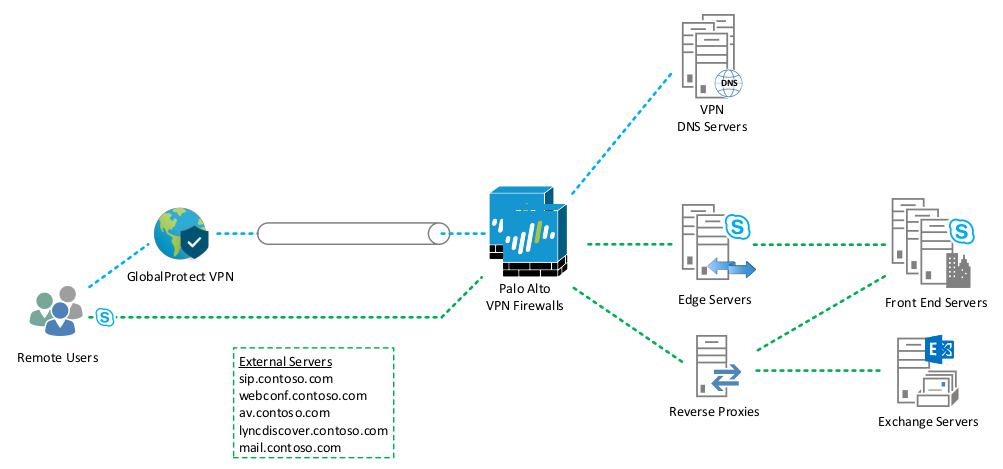
Here’s what the final outcome should look like for a GlobalProtect-Skype for Business-Exchange environment for split tunnel.
Of course, I fully admit this is really more of a legacy design with everything on-premises, but you could just as easily send the Exchange traffic to Office 365 in the split tunnel.
Thoughts on GlobalProtect Application Process Split Tunnel
While I had configured the traditional methods of doing split tunnel configurations (IP split tunnel and DNS servers), I’m still a little puzzled to the fact that the Palo Alto GlobalProtect application process split tunnel seemed to cause issues. My guess is that something in the way the Skype for Business client is designed prevents the process from being completely split tunneled, and I think this has to do with the way Skype for Business operates with Windows.
Basically, SfB gets a selection of candidates that it uses from the interfaces on the computer. In a GP split tunnel set up (with or without application process split tunnel configured), you’ll see ALL IP addresses (including the tunnel address) listed as candidates, and my suspicion is that Skype for Business still tries to use a tunnel interface, and sometimes it gets around the Palo Alto GlobalProtect application exclusion, and then that causes calls, application sharing, and even conferences to fail. I can’t show my own logs seeing this for security reasons, so you’ll have to trust me on that one.
Solution (tl;dr)
Here’s the quick solution for GlobalProtect and Skype for Business Split Tunnel
Create separate DNS servers for VPN clients and create the specific Skype for Business DNS records needed, and configure them for external IP addresses so that Skype for Business resolves external addresses and configures itself appropriately.
Create firewall rules that block traffic to/from the VPN network to internal Skype for Business and Exchange IP addresses. We want the SfB client to determine it can’t go inside for traffic.
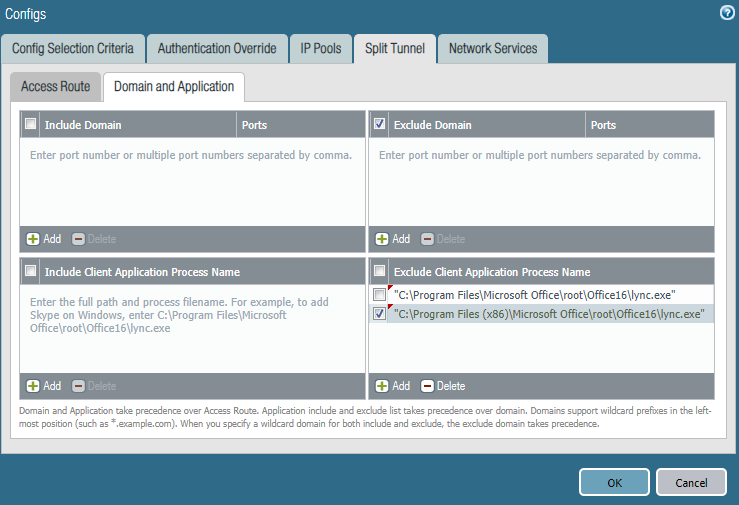
In Panorama or PANOS, under Network > GlobalProtect > Gateway > Agent > Client Settings > Client-Config > Split Tunnel > Exclude, configure all external SfB addresses so that the GP client doesn’t send traffic for those IPs through the tunnel. Alternatively, under Network > GlobalProtect > Gateway > Agent > Client Settings > Client-Config > Split Tunnel > Domain and Application > Exclude Domain, you could add the SfB external FQDNs (that said, IIRC, the stuff under ‘Domain and Application’ requires the GlobalProtect license…technically).