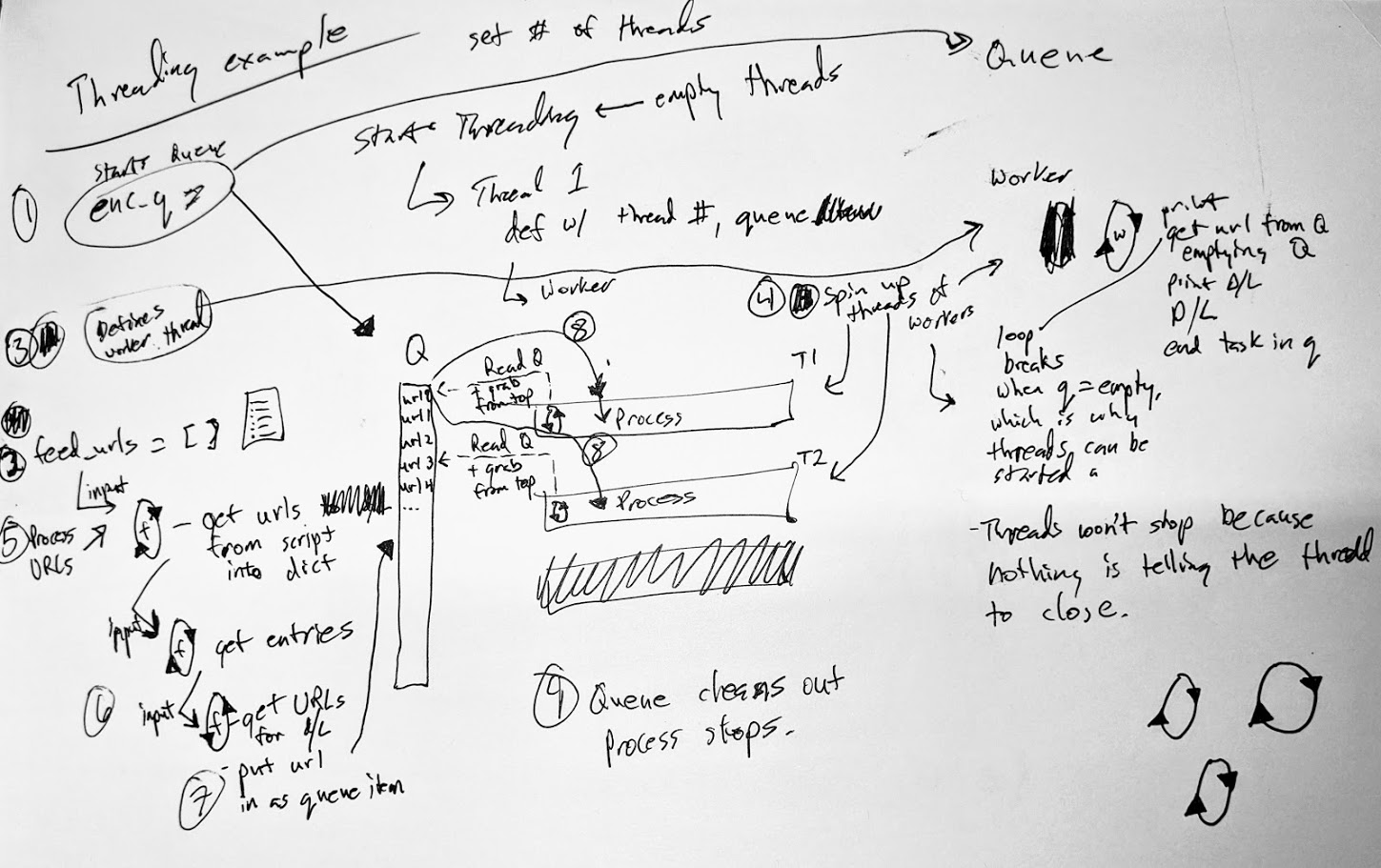
Note: I wrote this the evening of the event. Just getting around to publishing it now.
Another day has gone and another Cisco Engage Boise is behind us. This year at Cisco Engage Boise 2020, there was a very clear theme that I took away: network engineers need to be adding programability to their skill sets.

Note that I used the term programability and not automation. I think Cisco did a fantastic job making this distinction because the term automation gets thrown around a lot in engineering circles, often mistakenly conflated with scripting, or perhaps even with programability.
So what is programability and how is it different than automation? In my mind and in the context of network engineering, programability is an approach to network engineering that utilizes APIs and other tools within a software development framework to accomplish network engineering tasks. Automation, on the other hand, utilizes programability, but uses it to repeat tasks on regular intervals or based on events, both without the need of human interaction.
Cisco made it abundantly clear that future of networking involves incorporating programability into your skill sets, and they’re emphasizing this so much that they’re incorporating programability into the new certifications (click here or here for a great explanation). The engineering tracks will have 80% engineering and 20% programability, whereas the new developer-focused certifications will have 80% development, 20% engineering.

Cisco is also pushing this paradigm shift by offering a ton of resources on it’s learning platform DevNet, which has a lot of cool resources, and was also a topic that received a lot of airplay today.
Personally, I’ve long held the belief that programability is the future for network and system engineers alike, but to be completely honest, I’ve often been guilty of using the term automation to describe something that I didn’t have great word for. It’s great to see Cisco finally start pushing this, but I must say other vendors having been pushing programability and education on this topic for awhile now; why this is more relevant now is because the big player in this industry, Cisco, is pushing it now, so hopefully we’ll get better programability offerings such as APIs, structured data models, etc.
Sessions
Of course, it goes without saying that Cisco Engage Boise 2020 also had sessions, but to be honest, I don’t think there’s much to note that hasn’t already been mentioned on Reddit or discussed by Packet Pushers. There were a few different sessions to select from, but no tracks, so I went to sessions I thought were interesting for my interests right now (largely operational logistics and preventative analytics).
For conferences and sessions, I must say I have a bit of fatigue for security topics right now, especially on the networking front, so I avoided those. I don’t think anyone is really presenting anything new with security, and most of the fashionable topics are largely relevant to the higher tier of the NIST or CIS security frameworks. Most issues are addressed in the lower tiers, and it’s in those tiers where I’m interested.
That said, for the sessions I attended, I have just a few notes worth writing about:
- Zero Trust – Cisco’s philosophy to zero trust is like others: assume the traffic malicious until proven otherwise. Cisco basically believes there are three components that need to be addressed in order move towards a zero trust framework, so Cisco has a off-the-shelf framework for you to purchase and implement. The framework:
- Users need to be interrogated and challenged for access. Cisco product: Duo.
- Workloads need to be monitored and inspected for malicious activity. Cisco product: Tetration.
- Workplaces need to be secured and addressed. Cisco products: DNA, SD-Access and/or ISE.
- Hyperflex – This is Cisco’s hyperconverged infrastructure, and of note Cisco is going to be deploying Cisco Hyperflex Application Flatform (HXAP), which is a hypervisor to compete with the likes of VMware and will include it’s own Kubernetes implementation. Initially HXAP will be focused on containers, but eventually will grow to allow VMs and so forth. They noted that you’ll be able to avoid the ‘VMware tax’, but I’m certain that will just be replaced with the ‘Cisco tax’.
- DNA – DNA was definitely featured in a few of the sessions I attended, but I don’t care to go into the details of it. DNA basically is a platform to monitor and manage anything and everything about your Cisco network gear (well, only stuff that does 16.9, and basically on the hardware side is limited to 3850s and 9000 series gear). What really stood out to me about watching DNA in action for the first time was why Juniper made it’s Mist acquisition, because Juniper doesn’t really have a complete product to compete with DNA (yet, but they are making great strides). However, having features and having capabilities is one thing, but execution and proof of execution is a whole other thing — not to mention the price tag for the full vertical integration of everything to integrate with DNA.
Final Thoughts and An Evolving Mindset
When I signed up for Cisco Engage, I fully expected product evangelism — and I was not disappointed. I have a bit of an allergy to sales for some reason, but I’ve been challenging myself about this topic recently, and as a result, I found today’s conference quite useful.
That said, what I’m finally coming around to is the notion that I am a network engineer first (although I use engineer quite loosely here), and a user of products second. At a fundamentally high level, I am trying to solve networking problems for the organization I’m a part of, helping us accomplish our goals the best I think we can. It mostly doesn’t matter what products we deploy and use, as long as we can accomplish what the business needs us to.
I realize that’s not too much of a profound thought, but at times I feel like there’s a religious battle that continually takes place between vendors x, y, and z, aa, bb, etc. The reality is that, to paraphrase a podcast I was recently listening to, the technology landscape is much more diverse than just one or two vendors; there is plenty to learn from out there, and I think limiting yourself to one or even two vendors might force you into a paradigm/framework bubble that may not even be the best solution for your problems, maybe even stifling your ability to think more critically and out-of-the-box.
As a result, I’m trying to stay open to more ideas in networking, trying to not see every problem as a nail.